2.3.5.- Un programme de recherche et développement d'un vérificateur orthographique professionnel multilingue
Après avoir fourni dans les sous-chapitres précédents une méthode d'observation de la situation du domaine des industries de la langue, puis un exemple de fonctionnement, sur un domaine précis, de cette méthode, il m'a semblé indispensable de présenter également ce qui est l'objectif final de toutes ces études, à savoir un programme de recherches et développement pour un produit particulier du domaine des industries de la langue. Un tel programme ne se conçoit pas sans prendre en compte, de manière structurelle, de nombreux paramètres. Le principal de ces paramètres est que, puisqu'il s'agit d'un programme qui doit faire l'objet d'une décision de mise en oeuvre (et donc de financement), la présentation, le vocabulaire utilisé, l'organisation de l'argumentaire doivent correspondre étroitement à la rationalité des lecteurs (les décideurs eux-mêmes ou des experts mandatés par les décideurs). Il y a, pour le rédacteur, un objectif majeur (faire accepter le projet) auquel doit être soumis l'ensemble du document. Le texte du programme qui suit et dont je suis l'auteur a été effectivement présenté dans le cadre d'un appel d'offre de la Commission des Communautés Européennes. Il est donc destiné à être lu par un groupe particulier de fonctionnaires (que l'on appellera ici les fonctionnaires européens) qui, par certains côtés, est très proche du groupe de chargés de missions de la MIDIST dont l'ethnométhode a été présentée dans la première étude de ce chapitre.
Ce qui rapproche les fonctionnaires européens des chargés de mission de la MIDIST, c'est l'activité de définition d'une politique d'innovation technologique menée de façon parallèle à l'activité d'évaluation de projets. Ce qui fait différence, et elle est absolument énorme, c'est que la réalité concrète des buts personnels, des modes de communication, des structures administratives dans lesquelles ils évoluent, de l'organisation topologique des bureaux où ils travaillent, des processus de décision qu'ils suivent, du pays où ils habitent, de leurs cursus personnels (et infiniment d'autres points) sont totalement autres. J'ai eu l'occasion d'approcher souvent ces groupes de fonctionnaires européens entre 1982 et 1988 mais je n'en ai jamais fait partie pendant plus d'une à deux semaines d'affilée. Je peux donc dire que j'ai été membre au sens de Robert Jaulin, c'est à dire que j'ai eu des périodes d'échange, de partage complet avec ces groupes. Mais je n'ai pas eu suffisamment de contacts pour faire sur ce groupe un travail analogue à celui que j'ai pu faire sur le groupe des chargés de mission de la MIDIST. Les autres paramètres à prendre en compte lors de la rédaction d'un tel projet découlent directement du premier :
- la forme de la présentation doit être celle qui est imposée par les futurs décideurs. Un "cahier de rédaction" des projets faisant plus de 150 pages définissait étroitement cette forme.
- le choix de l'argumentaire, des partenaires du projet, des financements engagés doit correspondre le plus précisément possible à l'idée que le rédacteur se fait de l'attente des décideurs. En effet, l'obligation de mise en forme laisse très libre quant au contenu qui peut être plus orienté sur une recherche fondamentale que sur une recherche appliquée, sur une coopération recherche-industrie que sur une coopération entre organismes de recherche, sur une collaboration multinationale large ou restreinte, etc.
En effet, il y a une rationalité affichée par la CCE et qui demande que soient présentés des projets qui (entre autres) : "- contribuent à fournir à l'industrie européenne de l'information les technologies de base dont elle a besoin pour se développer dans les années 1990 ;
- contribuent à promouvoir la coopération industrielle européenne dans le domaine de l'industrie de l'information ;
- contribuent à favoriser l'émergence de normes et de standards acceptés internationalement."
Mais, dans le cadre de cette rationalité affichée, les décisions souveraines des fonctionnaires européens, tiennent compte de facteurs multiples, qui ne peuvent être affichés car contraire, par exemple à l'esprit égalitaire qui doit régner dans les rapports entre la CCE et les Etats. Ainsi, par exemple, à cause de l'inégalité du développement technologique des différents Etats membres de la CCE, les critères effectifs d'évaluation technique des projets issus des Etats les moins avancés sont moins contraignants que pour les projets issus des Etats les plus avancés. Pratiquement cela signifie que l'on a souvent intérêt à associer au projet un partenaire issu d'un Etat moins avancé technologiquement. Mais, comme les fonctionnaires européens connaissent cette attitude, il convient d'être prudent dans cette voie.
Pour des raisons évidentes de confidentialité industrielle et parce que cela ne présente ici aucun intérêt du point de vue de l'ethnométhodologie, le programme présenté ici a été rendu impersonnel, c'est à dire que l'ensemble des documents décrivant le programme ne sont pas fournis. La différence entre le programme effectivement proposé et celui qui est présenté ici est cependant très faible puisque le programme effectivement proposé devait être également impersonnel afin de ne pas influencer le travail des experts européens chargés de son évaluation. J'ai simplement retiré la première partie du document (qui devait être fournie séparément de la partie descriptive principale) donnant les noms des équipes partenaires du programme. Par contre je n'ai modifié ni la structure ni la rédaction du programme de recherche et développement afin que l'on puisse facilement comparer ce qui est dit dans le programme (à destination des fonctionnaires européens) avec les thèses du courant ethnométhodologie et informatique dont je fais partie et qui ont fait l'objet de la première partie de cette thèse. On verra, en particulier, comment sont présentées les bases scientifiques du programme et en quoi cette présentation s'efforce de prendre en compte le niveau supposé de réflexion des fonctionnaires européens pour ce qui concerne le traitement automatique du langage naturel. La différence de point de vue, et donc d'expression des problèmes et des moyens de les résoudre, qui résulte de la différence entre ce niveau supposé et celui que pourrait avoir un chercheur initié à l'ethnométhodologie est ici flagrante. Un exposé "ethnométhodologique" du problème de la vérification orthographique dans le cadre d'un tel programme de recherche et développement aurait posé deux problèmes pratiques majeurs au lecteur, fonctionnaire de la CCE, qui devait l'évaluer parmi une dizaine (ou une centaine) d'autres projets en quelques semaines : Il n'aurait pas eu le temps de lire un texte nécessairement long et il n'aurait pas eu le temps de "rentrer" dans la rationalité propre au texte.
Comme dans tous les projets de programmes de recherche et développement soumis à la Commission des Communautés Européennes, la langue utilisée peut être l'anglais ou la langue du pays proposant. Cependant, l'anglais est beaucoup plus parlé que le français par les fonctionnaires européens. C'en est même au point que dès que les règles du fonctionnement des instances communautaires le permettent, l'anglais est immédiatement utilisé comme langue véhiculaire. Ainsi, alors qu'il y a obligation de traduction simultanée dans toutes les réunions où sont présents des représentants mandatés des Etats membres, ce n'est pas le cas dans les réunions où ne sont présents que des fonctionnaires européens quelle que soit leur nationalité d'origine. Pour ces raisons règlementaires (mais également syndicales), les traducteurs seront toujours présents dans les réunions du premier type. Mais ils ne travailleront pas obligatoirement car, dès que la réunion est un peu technique, ou que les échanges sont rapides, l'anglais (ou, plus exactement une version de l'anglais particulière aux fonctionnaires européens, qui mélange allègrement à l'anglais d'Oxford des emprunts faits à toutes les langues communautaires) est adopté par chacun des présents. Les traducteurs jouent cependant un rôle très important car, si la discussion "durcit" entre les représentants officiels des différents Etats, ils reprendront alors leur langue d'origine, montrant ainsi que leur qualité principale est d'être représentant de leur pays et non pas fonctionnaire européen.
Par contre, dans les réunions internes où le sabir anglo-européen est pratiquement la seule langue utilisée, les traducteurs ne sont pas présents. La logique de l'identité nationale veut donc que les propositions de programme de recherche et développement soient faites en français. Cependant, comme, pour des raisons évidentes, l'expertise faite au nom de la CCE ne sera probablement pas faite par un français et que les négociations se passeront au niveau interne, une présentation partiellement en anglais est adoptée. Comme, par ailleurs, le dossier passera devant une commission de décision finale composée de représentants officiels des Etats, le gros du dossier est rédigé en français.
Une information importante consiste à identifier quelles seront les parties du dossier qui seront effectivement lues par les membres, fonctionnaires de la CCE, ou représentants des différents Etats. En effet, lorsqu'un débat contradictoire aura lieu entre le représentant de l'Etat d'où provient le dossier et les fonctionnaires de la CCE ou les représentants des autres Etats, l'objet sera de justifier, d'expliciter, d'argumenter le dossier sur la base de la rationalité du fonctionnement de la CCE et des contraintes propres à l'appel d'offre auquel il répond. Comme le montant total des financements distribuables à l'ensemble des projets est fixé à l'avance, par une décision des plus hautes autorités de la CCE (Le Conseil des Ministres européens), chaque représentant d'un Etat a fondamentalement intérêt à critiquer violemment tous les projets issus des autres Etats. Mais comme les décisions sont prises de façon consensuelles, il doit également se ménager des alliances qu'il utilisera lors de la négociation des ses dossiers. Bien évidemment aucun des participants au débat, sauf, parfois, le représentant de l'Etat d'origine du projet, n'a lu l'ensemble du dossier. C'est pourquoi le rôle de l'expert désigné par la CCE est si important. C'est pourquoi également il est important que toutes les parties résumant le dossier soient exprimées dans la langue susceptible d'être comprise par le plus grand nombre.
Cette proposition de programme de recherche et développement commence donc par une table des matières, un titre et un synopsis rédigés en anglais. Voici le contenu standard d'un dossier de programme de recherche et développement dans des secteurs liés aux technologies de l'information :
II.2.- Short synopsis of the project
II.3.- Brief summary of the project
II.4.- Objectives of the project
II.5.- How the project will comply with the aims and
objectives of ESPRIT
II.6.- Current state of the art in the field of the project
II.7.- Description of the project
II.7.1.- Main description
II.7.2.- Work plan and PERT of the project
II.7.3.- Major equipement and facilities required
II.7.4.- List of the deliverable items
II.7.5.- Description of the management techniques
II.7.6.- Relationships with other programmes
(Titre du projet)
A professional system for morpho-syntactic checking and correcting of spelling applied to multilingal texts.
Système professionnel de vérification et correction orthographique morpho- syntaxique de textes multilingues.
II.2.- Short synopsis of the project
The simplest texts (instructions and queries) submitted to a computer in natural langage will fail if they contain a spelling mistake. Large texts to be searched for information also have to be entirely corrected.
The project has the purpose of designing and implementing a professional system for checking and correcting of spelling through the use of large morpho-syntactic databases.
The spelling-checkers and spelling-correctors available on the market at the moment do not fulfill the necessary conditions for their use, with a sufficient level of efficiency, in several branches of industry as, for example, the publishing industry. This fact has several scientific and technical reasons :
- Hardware and software architectures do not take into account the specificities of linguistic processes, mainly in term of parallelism;
- General and specialised uniterms dictionaries are not large enough (about 300 000 forms instead of at least one million necessary) to really cover the variety of a given natural langage; the different ways to efficiently organise these very large dictionaries are not well known;
- Systems do not include compound forms dictionnaries and processes; They are not constructed and organised to be easily reusable in other applications.
In order to increase the productivity of the correction phase (which is actually mainly made by human operators) in text processing, the project will attempt to go beyond present limitations. This objective implies :
- to develop a set of hardware architectures and algorithms that allow a quick access to very large electronic dictionaries (about one million simple forms and several million compound forms for each treated langage : French, Spanish and Italian) ;
- to build the corresponding electronic dictionaries ;
- to develop functions and facilities to customize the system for different professional applications
- to implement a specialised version of the system in a professional publishing environment ;
- to design and realise a full set of tools that will give the possibility
to make an independant evaluation of the capacities of any checking or
correcting system.
Au cas où un débat viendrait cependant à s'établir, les participants vont, en séance, parcourir rapidement un élément suivant du dossier. Cet élément est le résumé du programme. Comme il faut que ce soit le représentant de l'Etat d'origine qui ait ici l'avantage, la rédaction se fait en français, ce qui a ainsi de bonnes chances de lui permettre d'avoir assimilé plus vite que ses collègues la teneur du programme et donc lui laisse quelques minutes pour préparer son argumentation.
Voici ce résumé :
(brève description du projet)
Le projet se compose de sept sous-ensembles principaux :
1.- Architectures matérielles
Dans ce sous-ensemble, seront élaborées et testées différentes architectures matérielles destinées à accroître le parallélisme tout en prenant en compte les spécificités des traitements linguistiques. Seront, en particulier examinées les architectures permettant de réaliser des traitement identiques sur des segments de données différents, des traitements différents sur des segments de données identiques, ainsi que des accès à des mémoires identiques par des traitements identiques ou différents.
2.- Architectures logicielles
Outre la mise au point des architectures logicielles qui correspondent aux architectures matérielles élaborées dans le sous-ensemble 1, on traitera dans ce sous-ensemble le problème de l'arbitrage entre des systèmes experts et des logiciels "classiques" de traitement linguistique. Par ailleurs, une architecture permettant au système de se reconfigurer dynamiquement en fonction des spécificités et évolutions des applications en cours sera mise au point. Enfin, de nouveaux modules de détection et de correction d'erreurs morpho-syntaxiques seront développés. Un travail de recherche sur les ergonomies des applications et sur les fonctionalités des mécanismes de mise à jour des dictionnaires et grammaires sera fait en vue de faciliter la réalisation, à partir des outils disponibles, de configurations adaptées à des classes d'applications différentes.
3.- Architectures de dictionnaires
Les dictionnaires existants seront considérablement augmentés, afin d'améliorer la couverture linguistique des langues choisies (français, espagnol, italien). De nouvelles techniques de compactages formels et linguistiques des dictionnaires seront élaborées et testées, ainsi que des méthodes d'accroissement automatique contrôlé. Des structures, principalement non-alphabétiques de dictionnaires seront systématiquement testées pour les architectures logicielles et matérielles développées dans les sous-ensembles 1 et 2, afin d'augmenter les performances des accès, principalement en génération de propositions de corrections.
4.- Traitements des mots composés
Aucun travail de recherche de grande ampleur n'a été réalisé à ce jour sur le traitement des mots composés alors même qu'apparaît l'importance croissante de cette classe d'objets dans le traitement automatique du langage naturel. L'accent sera mis sur les techniques d'élaboration de grands dictionnaires de mots composés, en particuliers dans les vocabulaires scientifiques et industriels. Des algorithmes de recherche et d'identification de candidats mots-composés dans des textes seront élaborés. Des méthodes de génération automatique et de normalisation des flexions et des graphies seront mises au point et testées. Différentes architectures de grands dictionnaires seront envisagées afin d'optimiser les accès et les mises à jour. Les liaisons entre dictionnaires de mots composés et dictionnaires de mots simples, d'une part, et entre dictionnaires de mots composés dans des langues différentes, d'autre part, seront examinées et feront l'objet de propositions de mise en oeuvre.
5.- Intégration
Dans ce sous-ensemble, deux démonstrateurs d'intégration des outils développés dans les sous-ensembles précédents seront développés. Le premier consistera en une implémentation dans une chaîne de production éditoriale multiusages de grande taille. Le second consistera une implémentation en sortie d'un système professionnel de lecture optique de caractères.
6.- Métrologie et validation
Une méthodologie générale de mesure des performances et de tests de systèmes de vérification ou de correction morpho-syntaxique de textes sera mise au point. Les logiciels correspondants seront développés de façon à être applicables au plus grand nombre possible de systèmes. Les corpus de référence seront construits pour les trois langues choisies dans le projet. Une méthodologie de développement de corpus semblables sera proposée pour l'ensemble des langues à alphabet latin.
7.- Analyse des erreurs
Une méthodologie d'analyse et de typologie qualitative et
quantitative des erreurs commises dans un couple (système de saisie-domaine
d'application) sera développée en prenant en compte la possibilité
de systèmes de saisie non-humains. Les logiciels correspondants
seront développés avec possibilité d'intégration
dans des systèmes d'auto-configuration dynamique d'automates vérificateurs
et correcteurs. Cette méthodologie fera l'objet de deux démonstrateurs
choisis dans les mêmes champs que les démonstrateurs du sous-ensemble
5.
Après ces éléments descriptifs destinés à jouer un rôle pendant les discussions de décision, le dossier contient une partie plus approfondie qui traite des objectifs scientifiques et techniques du programme, de sa conformité avec les objectifs de la CCE et de l'état de l'art dans le domaine.
Voici ces trois modules :
II.4.- The objectives of the project and the advance that it will represent in relation to known processes and techniques
(Objectifs du projet et progrès qu'il représente par rapport aux techniques et connaissances actuelles)
II.4.1.- Objectifs en matière d'architectures de matériels et de logiciels
II.4.1.1.- Une boîte à outils performante
Les vérificateurs et correcteurs orthographiques actuellement disponibles sur les systèmes de production éditoriale professionnelle sont limités par le fait qu'ils ne bénéficient pas d'architectures matérielles et logicielles adaptées à la complexité linguistique des problèmes traités. Ainsi, aucun système actuel ne fait appel au parallélisme dans les accès physiques aux dictionnaires, alors que la résolution de ce problème, qui semble accessible techniquement, est un point de passage obligé pour atteindre un niveau de performances professionnellement acceptable. Il en est de même pour ce qui concerne les algorithmes actuellement utilisés pour la compression et l'accès aux dictionnaires, ainsi que pour les différents traitements de détection et correction d'erreurs. Un exemple typique de chutes de performances améliorables par des procédures parallèles est la correction de lettres manquantes et début de mot lors d'une lecture optique de textes. L'objectif est d'améliorer au moins d'un facteur dix les performances, à tailles de dictionnaires identiques, des systèmes actuellement disponibles. Cette amélioration a pour principal objectif de permettre d'accroître la finesse et la diversité des vérifications ainsi que la pertinence des propositions de corrections tout en conservant des temps de traitement raisonnables.
II.4.1.2.- Une boîte à outils versatile
Le processus qui va de la saisie de textes à la fourniture des documents finaux prêts à imprimer est déjà largement automatisé. Ce processus fait appel à de nombreuses technologies de pointe et les solutions actuellement disponibles sur le marché sont relativement diversifiées. L'insertion, dans ce processus, d'automates qui vont prendre en charge partiellement ou totalement la fonction de vérification et/ou correction orthographique ne peut se faire sans tenir compte des importants investissements déjà réalisés dans les centres de production. Les outils résultants de ce projet devront autant que possible pouvoir être insérés dans les systèmes déjà existants ou à venir. Cette versatilité sera recherchée dans trois directions différentes :
- adaptabilité des outils dans des applications différentes d'une même activité (par exemple personnalisation du système pour utilisation en correction typographique chez un éditeur d'ouvrages de géographie, chez un éditeur de journaux sportifs, etc) ;
- adaptabilité des outils dans des environnements techniques différents pour une même application (par exemple, intégration du système de correction typographique dans les différents groupes de presse sportive dont les textes comportent de nombreux noms propres inconnus).
- adaptabilité des outils dans des activités différentes (par exemple, correction en sortie de lecteurs optiques de caractères, en entrée de systèmes d'aide à la traduction ou de systèmes d'interrogation de bases de données, en sortie de saisie humaine "au kilomètre" dans la presse, ou par des opérateurs ne connaissant pas la langue de saisie).
II.4.2.- Objectifs en matière de dictionnaires et grammaires électroniques
II.4.2.1.- Accroissement de la taille des lexiques-grammaires
Les plus importants dictionnaires utilisés actuellement dans des vérificateurs et des correcteurs automatiques ne dépassent pas 300 000 formes simples. Ce chiffre n'est d'ailleurs atteint à ce jour que pour deux langues (l'anglais et le français. Le cas de l'allemand est différent du fait de la forme des noms composés). Il est, de loin, insuffisant pour des applications professionnelles, même s'il a permis le développement des petits systèmes à performances limitées qui sont intégrés dans des progiciels de traitement de texte à usage bureautique.
L'objectif est de passer à un ordre de grandeur supérieur (environ un million de formes simples et plusieurs millions de formes composées par langue). Cet objectif n'est pas seulement un accroissement quantitatif mais aussi qualitatif : les expériences réalisées dans le passé montrent que le passage à de très grands dictionnaires demande impérativement un important travail d'analyse sur les structures morpho-syntaxiques de la langue, faute de quoi l'explosion combinatoire résultant de l'accroissement des dictionnaires provoque un écroulement des performances du système de vérification. C'est pourquoi, dans ce projet, ce ne sont pas des dictionnaires mais des lexiques-grammaires qui seront mis en oeuvre. C'est également pourquoi des organisations originales de dictionnaires (liées aux types de traitements mis en oeuvre) seront systématiquement élaborées et testées : organisations non alphabétiques, dictionnaires de mots retournés, de formes fausses, etc. Ce travail d'accroissement des dictionnaires portera sur les dictionnaires de mots simples et sur les dictionnaires de mots composés.
II.4.2.2.- Un système trilingue et extensible à d'autres langues
L'italien et l'espagnol n'ont pas fait, pour des raisons historiques, l'objet de descriptions morpho-syntaxiques aussi importantes que le français ou l'anglais. La proximité linguistique de ces deux langues avec le français et l'existence en Espagne et en Italie d'équipes utilisant les mêmes méthodologies de description que les équipes françaises permettent cependant de se fixer comme objectif la fabrication d'un système fonctionnant en français, espagnol et italien. Les architectures logicielles et matérielles aussi bien que la conception des lexiques-grammaires seront telles qu'en cas de succès du projet sur trois langues, une extension à d'autres langues européennes sera possible sans révision majeure des logiciels.
II.4.3.- Objectifs en matière de construction d'applications dans la branche professionnelle de l'édition
Les deux objectifs précédents permettront, lorsqu'ils seront atteints, de disposer d'une véritable boîte à outils à l'aide de laquelle il sera possible de fabriquer différents systèmes de vérification et correction morpho-syntaxiques de textes écrits dans les trois langues visées. L'intégration de ces outils dans des chaînes de production éditoriales existantes ou à venir est la finalité principale du projet. Ces intégrations pourront prendre des formes différentes. Ainsi, il y a actuellement une forte demande non satisfaite pour deux types de vérificateurs morpho-syntaxiques de niveau professionnel : des vérificateurs placés en sortie de lecteurs optiques et des vérificateurs placés en sortie de saisie humaine "au kilomètre". Dans le cadre de ce projet, il est proposé de réaliser des démonstrateurs d'intégration pour ces deux applications. Les outils développés dans le projet ont un potentiel d'utilisation qui dépasse largement le secteur de l'édition. En particulier, ils permettront de développer les futurs modules de vérification orthographique dans les progiciels bureautiques. Un champ également vaste d'applications existe dans les secteurs de la traduction assistée par ordinateur, des interfaces homme-machine pour les systèmes experts et les bases de données textuelles : il apparaît en effet que les analyseurs et interpréteurs des systèmes existants voient leur fonctionnement très perturbé par les erreurs morpho-syntaxiques contenues même dans les textes très courts soumis en entrée. Les implémentations dans ces différents secteurs ne seront pas réalisées dans le cadre du présent projet.
II.4.4.- Objectifs en matière de standardisation des mesures de performances
La vérification orthographique, même pour des interrogations simples, s'impose dans toute session de communication homme-machine : un défaut de robustesse au niveau de la graphie entraîne le rejet de la commande. Alors que l'interprétation sémantique des textes a fait l'objet de nombreux travaux, la correction orthographique a été, le plus souvent négligée. A cause de la jeunesse des applications en vérification et correction orthographique, il n'existe pas actuellement d'outillage complet permettant de mesurer et de comparer, dans un environnement donné, les performances des systèmes disponibles. Un objectif important du projet est de fournir une méthodologie de tests et les outils logiciels correspondants afin :
- de produire les corpus de référence dans un environnement donné en prennant en compte le couple (système de saisie/genre de textes saisis) ;
- de mener, dans cet environnement, une campagne de tests donnant des valeurs absolues ou comparées pour les différents paramètres de performance des systèmes en présence.
II.5.- How the project will comply with the aims and objectives of ESPRIT programme
(Cohérence du projet avec les buts et objectifs du programme ESPRIT)
II.5.1.- Ce projet entre explicitement dans le cadre des thèmes du type B du sous-ensemble "systèmes informatiques intégrés" dans le chapitre "Technologies d'application des TI" du programme de travail ESPRIT (22 juillet 1987). On trouve en effet, page III-24 de ce programme, le thème "Boîtes à outils pour soutenir la création, la modification et la correction des textes en langage naturel, systèmes d'édition par exemple" (projets III.2.1.5. dans la table des matière du programme de travail). On examinera, dans le chapitre suivant, les liens étroits qui existent entre ce projet et d'autres projets du programme ESPRIT.
II.5.2.- Ce projet se place clairement dans le cadre du développement de domaines prometteurs. Depuis trois ans, les industries de la langue sont apparues comme l'un des domaines clés des technologies de l'information, à la fois parce qu'elles sont transversales (la plupart des autres domaines des TI font ou feront appel à elles) et parce qu'elles sont incontournables (la plupart des autres domaines des TI ne pourront se développer que conjointement à elles). La CCE a joué un rôle de premier plan dans la prise de conscience de l'importance de ce domaine en organisant ou participant à des manifestations telles que le Colloque de Tours ("Les industries de la langue, enjeux pour l'Europe", Tours, février 1986), et en introduisant de façon quasi systématique dans ses différents programmes de R et D des travaux sur le traitement automatique du langage naturel écrit ou parlé dans les langues des Etats européens.
II.5.3.- Le projet proposé est un exemple de coopération entre différents secteurs des TI : nouvelles architectures logicielles et matérielles, traitement avancé du langage naturel, mise en oeuvre de grandes bases de données multilingues, création de technologies et d'outils offrant un potentiel d'utilisation dans une vaste gamme d'applications allant de celle proposée (la production éditoriale) à d'autres secteurs également prometteurs (TAO, interrogation de bases de données, systèmes experts).
II.5.4.- L'un des effets importants de ce projet sera de renforcer à long terme les capacités scientifiques en matière d'informatique linguistique dans trois Etats membres. En effet, une part non négligeable du financement de ce projet permettra aux trois centres de recherches impliqués de renforcer leurs équipes en y intégrant des jeunes chercheurs qui bénéficieront en même temps d'un environnement universitaire de haut niveau et d'étroites relations avec les industriels associés dans le projet. On peut également attendre de ce projet qu'il soit reconnu comme exemplaire par les responsables nationaux en matière de recherche en informatique-linguistique, à la fois par le fait qu'il est clairement piloté par la demande d'applications opérationnelles et qu'il fait appel à l'ensemble des niveaux de la recherche, des plus appliqués aux plus théoriques.
II.5.5.- Ce projet est un cas très favorable de complémentarité entre les compétences que peuvent mutuellement s'apporter des partenaires universitaires et des PME : les centres de recherches apporteront leurs connaissances en matière de linguistique- informatique (développement de grands dictionnaires, algorithmes de traitements linguistiques) et de nouvelles architectures de machines. Les PME apportent leur savoir-faire en matière de développements et d'intégration de systèmes et, surtout, des environnements d'implémentation réels. Il est important de préciser ici que tous les partenaires du projet ont une longue expérience de la coopération université-industrie et qu'ils en connaissent les difficultés.
II.5.6.- Bien que limité à trois langues communautaires, le projet permet de développer des compétences qui seront exploitables dans un cadre largement international. Tout d'abord parce que deux des langues proposées (le français et l'espagnol) ont une couverture géographique extra-européenne (et l'extension au portugais est très rapide à mettre en oeuvre), mais aussi parce que les architectures matérielles seront indépendantes des langues traitées et les architectures logicielles seront en majeure partie ré-exploitables sur de nombreuses autres langues que les langues latines, comme des études préliminaires sur le grec et le russe l'ont montré.
II.5.7.- Ce projet est bien cohérent avec l'objectif ultime d'ESPRIT qui consiste à intégrer les TI dans les systèmes d'application. Cette cohérence apparaît comme partie intégrante du projet : les outils réalisés constitueront un moyen puissant d'amélioration de multiples systèmes d'application dans de nombreux secteurs ; les deux démonstrateurs d'intégration dans le secteur de l'édition permettront de prouver la possibilité de gains en productivité et en qualité ainsi que de positionner des entreprises européennes sur ce créneau.
II.5.8.- Ce projet est, par essence, européen. Il ne peut
être pleinement réalisé sans l'intervention de compétences
qui sont réparties dans tous les Etats membres et qu'aucun d'entre
eux ne détient entièrement. Le fait que le projet ne commence,
pour d'élémentaires raisons de faisabilité, qu'avec
des partenaires de trois Etats membres n'interdit en aucune sorte de plus
larges développements ultérieurs. En cas de succès,
les produits résultants de ce projet devraient, par ailleurs, trouver
dans la CCE l'un de ses premiers clients, en raison de l'importante production
de textes multilingues qu'on y trouve en même temps que l'impérieuse
nécessité d'une grande qualité éditoriale et
d'une optimisation maximale des ressources humaines.
II.6.- Current state of the art in the field of the project
(Etat de l'art dans le domaine du projet)
Le problème que tente de résoudre un vérificateur orthographique s'énonce simplement de la façon suivante : étant donné un texte, le parcourir et identifier les mots qui sont incorrects. On distingue habituellement le vérificateur orthographique (en anglais, "spelling checker") du correcteur orthographique (en anglais, "spelling corrector") qui, de plus, s'efforce de trouver, pour chaque mot incorrect, un remplaçant correct.
Cette façon de poser le problème exclut l'activité de réécriture stylistique ou visant à améliorer la compréhension du texte par le lecteur (ou même à le rendre compréhensible quand il ne l'est pas...).
Cette façon de poser le problème suppose que la forme correcte des mots est connue. Or, d'une part il est extrêmement difficile et onéreux d'accéder à l'ensemble des connaissances disponibles sur une langue (et donc on trouvera des "trous linguistiques" importants dans tous les systèmes commercialisés) et, d'autre part, le nombre de mots non normalisés ou "normalisés" de plusieurs façons divergentes est très élevé surtout si on considère des ensembles qui, comme les mots composés, ne sont quasiment pas normés.
En l'état actuel des connaissances, il n'existe aucun système dans aucune langue qui soit capable de réaliser entièrement automatiquement l'une des deux fonctions de vérification ou de correction (même en considérant la très forte restriction indiquée) avec une fiabilité comparable à celle d'un professionnel humain. Le problème est du même ordre de complexité que celui de la traduction automatique.
Les travaux scientifiques concernant la vérification et la correction orthographique automatiques sont très anciens, puisque des articles, encore aujourd'hui considérés comme importants, sont publiés dès 1959. Initialement orientés vers la correction généralisée d'erreurs en sortie de lecteurs optiques, ces travaux se sont progressivement fixés des objectifs de plus en plus modestes, suivant en ceci une évolution très parallèle aux travaux en TAO :
- une première phase de sous-estimation de la difficulté du problème, conduisant à des promesses inconsidérées et à des échecs retentissants ;
- une seconde étape de quasi abandon des travaux sur le langage naturel au profit de travaux sur des langages artificiels (les détecteurs d'erreurs dans les compilateurs et interpréteurs de langages de programmation), accompagnée du développement des travaux sur les descriptions formelles des langues naturelles ;
- une troisième étape où, sur la base des connaissances engrangées lors de la seconde étape, des travaux visent à résoudre au mieux pour des langues naturelles les différents types de problèmes identifiés (mais non toujours résolus) pour des langues artificielles, ainsi qu'à tenter des applications restreintes en abandonnant la possibilité de généralisation ultérieure (en travaillant sur des corpus de textes en langage contrôlé et/ou dans des domaines très restreints) ou les performances et la fiabilité (en travaillant sur des corpus généraux).
On est ainsi progressivement passé de l'objectif de correcteur orthographique entièrement automatique à l'objectif de l'automate qui fournit une assistance à l'opérateur humain en identifiant d'éventuelles erreurs et, parfois en proposant des formes corrigées. Les systèmes actuellement commercialisés fonctionnent en mode interactif, l'opérateur devant valider chaque détection d'erreur et choisir l'une des propositions de correction. En effet, si le remplacement d'une erreur identifiée par une correction était fait automatiquement, les erreurs ainsi introduites seraient considérablement plus nombreuses que les erreurs initialement existantes.
Et la qualité d'un système n'est plus tant désormais celle de l'automate seul que celle du couple opérateur-automate. C'est ainsi que les vérificateurs actuellement commercialisés sont considérés comme utiles et rentables, même s'ils ont des performances (en terme de ratio erreurs existantes/erreurs identifiées) peu élevées. Ainsi, par exemple, de nombreux vérificateurs actuels ne contrôlent pas les mots dès qu'ils contiennent une seule majuscule, car cela conduit à "déranger" l'opérateur aussi bien à chaque début de phrase (ce qui n'est généralement pas justifié par une erreur orthographique) qu'à chaque sigle ou nom propre (généralement non contenu dans le dictionnaire des formes autorisées).
Ce que peuvent faire les vérificateurs actuellement commercialisés ?
Plusieurs techniques très différentes de détection d'erreurs sont utilisées. Les plus anciennes ne sont pas les moins efficaces mais elles sont en cours d'abandon car structurellement limitées.
L'une des plus connues est celle qui a été utilisée dans TYPO, un vérificateur qui fonctionne sous UNIX. L'idée est que les séquences de deux et trois caractères réellement utilisés dans l'écriture d'une langue sont beaucoup moins nombreuses que la combinatoire sur deux et trois caractères de l'alphabet. De plus chaque doublet et triplet existant réellement peut être, par analyse d'un grand corpus, affecté d'un coefficient de probabilité d'occurrence. L'analyse du texte à corriger consiste à détecter les doublets et triplets dont l'occurrence est anormale, l'expérience indiquant que les mots contenant des fautes de frappe (inversions, erreurs, omissions et redoublements de lettres qui représentent 80% des fautes) auront un fort indice d'anormalité. Afin d'améliorer la performance du système, TYPO contient un dictionnaire des 2500 mots les plus courants de la langue. Comme l'expérience montre que sur un texte en anglais (non littéraire) de 10000 mots, on ne compte, en moyenne que 1500 mots différents, une comparaison entre la liste des mots jugés statistiquement anormaux et le dictionnaire réduit considérablement la liste des "erreurs" proposée à l'usager.
Cette technique, plus statistique que linguistique, est très caractéristique des produits de l'informatique appliquée aux langues qui ont été réalisés entre 1960 et 1980. Ses limites en sont évidentes même si elle donne parfois de meilleurs résultats en vitesse d'exécution que des techniques plus "linguistiques" et bien qu'elle soit très facile à transférer d'une langue à une autre.
La technique de plus en plus utilisée aujourd'hui est la comparaison de chacun des mots du texte à un mot d'un (ou plusieurs) dictionnaire de grande taille fabriqué à l'avance. Les performances de cette technique dépendent de la taille et de la qualité du dictionnaire. Deux dictionnaires sont habituellement utilisés : un dictionnaire général, fourni par le vendeur du logiciel et un dictionnaire personnel contenant le vocabulaire souvent utilisé par l'usager (et créé par ce dernier).
Parfois, comme dans le vérificateur orthographique de WORD, un troisième dictionnaire, également créé par l'usager (et appellé "dictionnaire du document"), contient le vocabulaire exclusivement utilisé dans le texte en cours de correction (afin de ne pas surcharger les deux dictionnaires précédents et de prendre en compte des cas particuliers : fautes volontaires, noms propres, etc.). D'autres structures de dictionnaires sont également utilisées.
Par exemple, un premier dictionnaire, en mémoire centrale, contient les formes (de 2000 à 5000) statistiquement les plus utilisées dans la langue. Un second dictionnaire, également en mémoire centrale, contient le vocabulaire souvent utilisé par l'usager et un troisième dictionnaire, le plus complet possible, est placé sur disque externe.
Les dictionnaires de l'usager sont de simples listes de mots. Le dictionnaire général a une forme un peu plus complexe (dans les vérificateurs les plus performants, car pour les autres, il ne s'agit également que d'une liste de mots...). Sa complexité est de deux ordres :
- le dictionnaire ne contient pas seulement des mots mais aussi des préfixes, affixes et suffixes, ce qui a le double avantage de fortement réduire l'espace mémoire occupé (durée, durable, durablement est stocké sous une forme du type dur-ée, -able-, -ment ) et de permettre, sous certaines conditions d'accepter des néologismes locaux (pratique courante en anglais). Cette technique rencontre de très nombreuses limites qui ne sont souvent gérables que par énumération (par exemple, l'accent change de grave en aigu entre misère et misérable ) ;
- le dictionnaire ne contient pas seulement des mots et portions de mots mais aussi quelques marqueurs morphologiques et parfois syntaxiques qui servent à activer des algorithmes liés à certaines formes (par exemple, les conjugaisons des verbes, les pluriels réguliers, etc.).
Les vérificateurs actuellement commercialisés utilisent les dictionnaires de la façon suivante :
Ils parcourent le texte à la recherche des caractères considérés comme séparateurs de mots (espaces blancs, virgules, apostrophes...). Et ce sont les suites de lettres comprises entre les séparateurs qui sont comparées, une à une, aux formes contenues ou dérivées dans les dictionnaires. On voit facilement que cette méthode (qui a l'incontestable avantage de la simplicité) ne couvre que très grossièrement la diversité linguistique. Ne sont pas détectées, par exemple, les erreurs sur les mots contenant des espaces blancs, tel que "chêne de télévision" ; le problème de l'identification des séparateurs n'est généralement pas bien résolu car les multiples cas particuliers ne sont pas correctement énumérés (par exemple l'apostrophe n'est pas un séparateur dans "aujourd'hui").
Bien entendu, cette technique de vérification, de même que les techniques "non linguistiques" précédemment évoquées, exclut la détection d'une faute d'accord en genre ou en nombre, ou de conjugaison (puisque que les formes écrites correspondent à une forme possible contenue dans les dictionnaires).
A quoi peuvent donc servir des vérificateurs aussi limités ?
Ils détectent principalement les fautes de frappe : inversions, omissions, erreur et redoublement de lettres. Ces fautes sont les plus courantes chez les usagers non professionnels de claviers. Et la quasi inefficacité des actuels vérificateurs sur les "vraies" fautes d'orthographe explique qu'ils ne soient pas utilisés en milieu professionnel : les correcteurs humains professionnels considèrent que les fautes de frappe "sautent aux yeux" et qu'ils n'ont pas besoin d'un système qui attire leur attention dessus, car ce mode de travail conduit l'humain à ne plus faire attention aux autres fautes (à cause de la segmentation de la lecture-compréhension induite par les interruptions de la machine).
Evidemment, les fabricants de vérificateurs orthographiques se sont efforcés d'améliorer les performances de leurs systèmes. Mais dès que la simplicité biblique des vérificateurs de base est abandonnée, de grandes difficultés sont rencontrées, dues à la méconnaissance quasi-totale des concepteurs en matière linguistique ou au coût de la résolution correcte des problèmes rencontrés.
Un exemple classique des difficultés rencontrées est l'introduction d'une nouvelle règle orthographique. Faute de connaissances linguistiques suffisantes, elle est introduite de façon trop générale et provoque l'identification de fausses erreurs en grand nombre. Mais, dès que l'on tente d'affiner la règle, on s'aperçoit que personne ne la connaît vraiment, qu'elle n'est pas suffisamment formalisée pour une implantation sur une machine, et que le concepteur du vérificateur doit faire lui-même le travail considérable de recherche des mutiples situations linguistiques possibles. S'il fait ce travail, il s'aperçoit rapidement que le nombre de règles nouvelles à introduire croît de façon considérable, augmentant les différents paramètres du temps de traitement. L'un des aspects principaux de cette spirale catastrophique est la croissance du dictionnaire qui atteint vite des volumes incompatibles avec :
- les algorithmes d'accès aux données : les meilleurs algorithmes (utilisables sur des grands volumes de données) d'accès à des listes de formes sont en (n x log(n)), ce qui devient vite très lent.
- les espaces disponibles en mémoire centrale : les importants facteurs de compression obtenus pour les dictionnaires dans les vérificateurs simples se réduisent rapidement devant l'avalanche des cas particuliers. Les dictionnaires ne peuvent alors plus résider de façon linéaire en mémoire centrale ;
- la technologie des mémoires de masse (les disques les plus rapides demandent 15 ms par accès, généralement 30 ms et il faut plusieurs accès pour un seul mot...).
Outre les effets énumérés ci-dessus, l'accroissement des dictionnaires a d'autres effets négatifs. Par exemple, la fonction qui propose des mots possibles en remplacement d'un mot identifié comme éventuellement erroné perd rapidement toute efficacité car, le dictionnaire croissant, le temps de recherche des mots-candidats devient extrêmement long (de même que leur nombre). Cette fonction devient donc optionnelle dans le système et n'est, en pratique, pas utilisée. Une variante consiste à arbitrairement considérer que les deux premières lettres du mot identifié comme faux sont correctes, de façon à limiter la recherche de candidats-mots remplaçants, mais on voit bien qu'en s'engageant sur cette cette voie, le fabricant du vérificateur (Spell sur les systèmes DEC) a été contraint au "bricolage" de mauvais aloi.
L'état de la technique peut donc se résumer de la façon suivante : après une vingtaine d'années de recherche, on connait plusieurs techniques de vérification orthographique. Les techniques linguistiques (au sens morpho-syntaxique) deviennent de plus en plus utilisées car elles ne sont limitées que par la finesse des descriptions de la langue. Le niveau actuel de finesse des descriptions est insuffisant pour un usage professionnel et, en accroissant la finesse, on accroît considérablement les problèmes d'implémentation pratique.
L'utilisation de systèmes travaillant au niveau sémantique (avec une "compréhension" du domaine traité dans le texte) est aujourd'hui totalement exclue à cause de l'aspect encyclopédique des applications commercialisables. Cependant les techniques issues de l'intelligence artificielle sont largement utilisées pour réaliser des modules de traitement spécialisés. La construction et le paramétrage de systèmes experts affectés à la résolution de micro-problèmes de morphologie ou de syntaxe est en effet une solution fréquente puisqu'elle permet d'avancer même lorsque le problème n'est pas entièrement résolu, ce qui est le cas général.
Trois raisons majeures expliquent l'absence sur le marché de produits de vérification et correction orthographiques de niveau professionnel :
- les descriptions de langue utilisées par les actuels fabricants de vérificateurs sont insuffisantes pour un usage en milieu professionnel et ceux-ci ne possèdent pas le niveau scientifique requis pour les réaliser ;
- les investissements qu'il faut réaliser pour obtenir une description suffisamment fine des trois langues dépassent les possibilités de la plupart des acteurs industriels du domaine ; la réalisation de telles descriptions ne se limite en effet pas à la fabrication de grands dictionnaires, tels ceux fabriqués par les éditeurs pour l'usage par des humains, mais demande également d'importants savoir-faire en matière de structuration, de maintenance et d'utilisation des dictionnaires. Le défaut de ces savoir-faire est la raison principale des limitations des systèmes actuellement commercialisés. Les listes de mots facilement obtenues par analyse des dictionnaires existants ou par accords avec leurs éditeurs donnent une fausse impression d'exhaustivité et masquent la complexité des autres problèmes, ce qui explique le grand nombre de tentatives connues et le faible nombre de produits finalement commercialisés. Le nombre des entreprises dans le monde entier qui fabriquent des systèmes de vérification ou de correction orthographique (principalement destinés à être intégrés dans des progiciels de traitement de textes) est très faible (moins de cinq pour la langue française, qui est cependant l'une des mieux traitées).
- les seules descriptions suffisamment fines du français, de l'espagnol ou de l'italien, faites sur financements publics (depuis une vingtaine d'années pour le français, depuis une dizaine d'années sur l'italien et depuis cinq ans sur l'espagnol) sont réalisées dans les centres de recherche partenaires du projet. Or, ces centres de recherche ne diffusaient pas jusqu'à présent les résultats de leurs travaux car ils les considéraient comme insuffisants. Ce n'est que depuis deux ans environ que ces centres de recherche ont entrepris de transférer à l'industrie leurs méthodes et leurs données. C'est dans le cadre de ces contacts que s'est constitué le consortium qui propose le présent projet.
Les constatations précedentes pourraient amener à penser qu'il n'existe aucun produit en dehors des vérificateurs intégrés dans les systèmes de traitement de textes qui sont commercialisés par tous les éditeurs de logiciels à grande diffusion (principalement Microsoft, Ashton Tate et Borland, ce dernier ayant mis sur le marché, à partir de données linguistiques fournies par Larousse, un excellent petit vérificateur intégré - fonctionnant uniquement en français - dans le logiciel Sprint).
Etant donné l'ampleur du marché potentiel (tout organisme ayant à manipuler de grandes quantités de textes !) il eut été étonnant que les "majors" de l'informatique n'ai développé aucun produit ou, du moins, mené des recherches approfondies. Plusieurs entreprises de niveau mondial sont en effet actives sur le secteur. Il s'agit en tout premier lieu d'IBM. Cette entreprise est probablement celle qui, avec ATT, a fait les plus lourds investissements en R et D dans le domaine du traitement de la langue naturelle. Pour IBM, les Centres scientifiques de Yorktown Heights et de Paris et pour ATT, les Bell Labs, sont reconnus comme étant, en nombre de chercheurs, parmi les plus importants centres de R et D dans le domaine. L'activité de ces centres porte sur tous les aspects du domaine, depuis la traduction automatique jusqu'à la machine à écrire à entrée vocale, en passant par l'interrogation de bases de données.
Bell propose en standard l'utilitaire "Spell" dans ses systèmes d'exploitation Unix. Les limites de ce logiciel, qui ne fait plus l'objet de nouvelles améliorations depuis trois ans au moins, sont les mêmes que celles des vérificateurs fonctionnant sur micro-ordinateurs.
Un autre produit des Bell Labs est beaucoup plus intéressant. Il s'agit de "Writer's Workbench". Ce produit, a été mis au point aux début de 80. En 1981, il a été testé par deux entreprises du groupe (ATT Long Lines et Western Electric), puis, en 1982 il a été introduit à l'Université du Colorado dans les enseignements de bureautique cependant qu'il était commercialisé par Western Electric principalement dans l'administration américaine. Ce produit n'est pas très intéressant du point de vue scientifique et Bell ne le présente d'ailleurs pas comme un système issu de ses travaux en intelligence artificielle. En effet Writer's Workbench ne fait aucune analyse linguistique approfondie des textes et ne contient aucun module de traitement sémantique. Il offre cependant une étonnante variété de fonctions d'assistance stylistique et orthographique simples. Par exemple, l'un de ses modules signale les trop nombreuses répétitions d'un même terme. Un autre vérifie la ponctuation, un troisième prévient l'usager quand il fait des phrases trop longues, etc. Bien entendu, il contient un vérificateur orthographique, un module de conjugaisons, un dictionnaires de formes irrégulières. Il contient également un ensemble d'outils statistiques qui donnent des informations sur les textes rédigés afin de permettre une mesure de l'évolution de la compétence rédactionnelle de l'usager. Ce logiciel, qui a clairement un but éducatif, dialogue avec l'usager en donnant des conseils facultatifs. Son intérêt réside principalement dans sa richesse fonctionnelle et dans l'important travail ergonomique fait pendant sa mise au point. Il ne fonctionne qu'en anglais.
Un autre produit ayant le même objectif d'assistance à la rédaction est commercialisé par Smart AI Corporation. C'est un petit système expert (1500 règles et un dictionnaire de 50 000 termes dans un domaine spécialisé) qui simule le comportement d'un rédacteur technique moyen et qui fournit des conseils stylistiques et syntaxiques. Il ne fonctionne que sur un sous-ensemble de l'anglais dans un domaine technique défini à l'avance. Il est assez caractéristique des produits issus des travaux en IA qui ne peuvent en aucune sorte s'avancer sur le domaine de la vérification orthographique en milieu professionnel (à cause du caractère immédiatement encyclopédique des documents traités).
On trouve chez IBM, avec le projet Epistle, un travail de beaucoup plus grande ampleur. Epistle n'est pas présenté par IBM comme un produit mais comme une activité de recherche qui n'est, pour l'instant, pas susceptible de déboucher sur des produits. Ce qui différencie principalement Epistle des deux produits précédents, c'est le fait qu'Epistle fait une analyse syntaxique approfondie des textes (en anglais exclusivement), utilisant un dictionnaire estimé à 70 000 termes et une grammaire de plusieurs milliers de règles.
L'objectif pricipal d'Epistle est de trouver dans une phrase syntaxiquement incorrecte ce que l'usager peut avoir voulu dire et de lui expliquer ce qu'est l'erreur et ce qui serait la forme correcte. Lorsque le système trouve une erreur syntaxique, il tente, en relachant les contraintes de l'analyse, de trouver une forme syntaxiquement correcte. S'il la trouve, il l'expose à l'usager. Il combine cette analyse syntaxique avec une analyse stylistique proche de celle effectuée par Writer's Workbench. Epistle fonctionne sur une machine virtuelle de 4 Mbyte sous VM. L'analyse syntaxique est faite sur une machine dorsale. Le dictionnaire de base (70 000 termes) occupe environ 3 Mbytes. Le dictionnaire de formes avec ses logiciels associés occupe de 20 à 30 Mbytes.
Lors de tests faits par IBM sur un corpus de 2500 phrases extraites de lettres et rapports commerciaux, le temps de traitement moyen d'une phrase était de 10 secondes CPU sur un IBM 30XX. L'analyse syntaxique échouait dans 40% des phrases. Des améliorations considérables ont été apportées à ce système depuis ses premières versions mais, aujourd'hui encore, il n'est pas envisagé de l'utiliser autrement que comme un outil d'expérimentation.
A cause de son importance, le projet Epistle peut être pris comme référence comparative dans le définition d'autres projets. Dans le projet que nous présentons, nous avons délibérément choisi de ne traiter qu'un sous-ensemble d'Epistle. Ce choix résulte de la volonté d'accroître la "robustesse" industrielle et scientifique du projet ainsi qu'il est décrit ci-dessous :
- Bien que le projet proposé dans le cadre de ce quatrième appel d'offre ESPRIT soit clairement de la recherche précompétitive et non du développement de produit, les partenaires ont une volonté affirmée de mettre en marché des produits commercialisables dans un délai court après la fin du projet. Il est aujourd'hui très généralement admis que l'ambition de projets comme Epistle interdit cette possibilité à moyen terme (ce qui ne veut pas dire qu'IBM n'apprend pas énormément en menant cette activité de recherche). Exprimé en d'autres termes, la généralité du projet Epistle se paye par une fragilité certaine en termes d'implémentations industrielles, choix qu'IBM peut peut-être se permettre mais pas les partenaires du projet.
- Le sous-ensemble d'Epistle qui est traité dans le projet proposé pour ESPRIT en constitue tout à la fois le noyau et la difficulté principale. En effet, l'habillage ergonomique ou les modules de traitement stylistique, sans être simples, ne posent pas de problèmes scientifiques majeurs, alors que les chercheurs d'IBM eux-même reconnaissent que la qualité des dictionnaires, des grammaires et des systèmes d'analyse morpho-syntaxique forment la base réelle de leurs travaux et que les obstacles sur lesquelles ils achopent sont dus principalement à des faiblesses sur ce noyau. IBM a d'ailleurs, à plusieurs reprises, offert à deux des partenaires du projet de leur acheter leurs dictionnaires et leur savoir-faire ainsi que de les associer dans des projets sur ce domaine.
Exprimé en d'autres termes, la généralité du projet Epistle se paye par une certaine fragilité en terme de choix des orientations scientifiques. En faisant une restriction de ce projet à son noyau, les partenaires du présent projet augmentent la robustesse scientifique de leur action de R et D (et donc en limitent le risque et peut-être même en diminuent le coût).
Plusieurs études ont conclu à la faisabilité et à la nécessité de lancer des projets de vérificateurs et correcteurs morpho-syntaxiques sur les langues européennes. On peut citer, en particulier les études, généralement considérées comme de référence, faites par la Mission "Industries de la langue" du Ministère français de la recherche, par Cognos pour le Gouvernement Canadien et l'étude multiclient Ovum. Ces études insistent toutes sur l'importance des investissements qui seraient nécessaires si le projet partait de zéro et donc sur l'importance du choix des partenaires producteurs de dictionnaires (le coût des dictionnaires représente, dans toutes ces études, la part principale des dépenses) qui doivent avoir un capital en données et en savoir-faire très important.
Dans l'étude Ovum, dont les chiffres ont été repris dans toutes les autres études sur le sujet, il était prévu que les premiers produits, de niveau professionnel, commenceraient à apparaître aux Etats-Unis dès 1987 et seraient intégrés dans des applications variées (la TAO était citée comme l'une des premières) en 1988-89. Aujourd'hui, aussi bien les experts des cabinets d'étude qui sont en train de rédiger les prochaines évaluation (INK, par exemple, qui publiera une étude au mois de juin 1989) que les analystes dans les instances nationales de pilotage de la recherche repoussent cette échéance à 1992-95 à cause de l'indisponibilité de grands dictionnaires dont la réalisation prend beaucoup plus de temps qu'il était initialement prévu. Ce problème est d'ailleurs exprimé dans des termes identiques pour le secteur de la TAO où tous les industriels impliqués se livrent depuis deux ans à une chasse frénétique aux dictionnaires performants.
Plusieurs des partenaires de la présente proposition ont développé des projets qui leur ont permis d'acquérir une importante expérience préalable. Ainsi deux des partenaires du projet proposé ont déjà réalisé le prototype d'un système de vérification orthographique destiné à être intégré dans la prochaine génération de postes de travail bureautique (4 à 16 Mo de mémoire centrale, écran graphique A4 ou A3, multiprocesseurs 68020 ou 80386 et système UNIX). Ce prototype, qui sera industrialisé au second semestre 1988, ne traite que les algorithmes du noyau et les dictionnaires de base (500 000 formes environ à ce jour, ce qui est déjà le double des meilleurs systèmes actuellement commercialisés). Il ne contient aucune parallélisation des processus et ne traite qu'une seule langue.
Par ailleurs, trois partenaires du projet ont en cours de très importants programmes de développement de dictionnaires électroniques et ont réalisé de multiples maquettes non industrialisables pour résoudre des problèmes partiels en vérification orthographique ou en construction de très grands dictionnaires. L'expérience de ces trois partenaires en matière de dictionnaires et grammaires électroniques est reconnue comme étant de tout premier niveau mondial sur leurs langues respectives. Deux des partenaires industriels ont une part importante de leur activité qui consiste à développer, construire et commercialiser des équipements informatiques. L'un d'entre eux est spécialisé dans les équipements destinés à l'industrie de l'édition, et l'autre dans les systèmes temps réel à très hautes performances. Deux partenaires du projet ont pour activité principale la composition ou l'édition de textes et ont mené, depuis dix ans, de nombreuses expérimentations visant à améliorer la productivité de la chaîne éditoriale : nouvelles techniques de césure, de mise en page automatique, d'organisation des réseaux locaux de saisie, d'interconnexions d'équipement hétérogènes, etc.
Le projet proposé pourra fournir des résultats directement exploitables à plusieurs autres projets tels qu'ils sont définis dans le programme de travail ESPRIT.
Ceci est particulièrement évident pour les sous-ensembles II.2.6. "interaction homme/machine" et II.2.7. "grandes bases de connaissances" du chapitre "génie de la connaissance". Mais pratiquement tous les thèmes de ce chapitre font appel, sous une forme ou sous une autre à des modules logiciels ou à des données issues du projet proposé : pour certains, une boite noire placée en interface avec l'usager filtrera les erreurs morpho- syntaxiques, causes de mauvais fonctionnements dans les systèmes manipulant de la connaissance. Pour d'autres, les dictionnaires et automates de traitement linguistique constitueront une part active des systèmes (il est plus facile et plus rapide de reconnaître syntaxiquement le mot composé "tube cathodique" pour faire ensuite le traitement sémantique adéquat que de commencer à faire deux traitements sémantiques sur "tube" et "cathodique" pour en arriver à reconnaître sémantiquement "tube cathodique" et commencer alors le traitement sémantique adéquat : un tube cathodique n'a en effet rien d'un tube et n'est pas plus cathodique qu'anodique. Ce phénomène est extrêmement fréquent, en particulier dans le vocabulaire technique).
Dans le chapitre II.4. du programme de travail ESPRIT, les sous-ensembles II.4.3., II.4.4. et II.4.5. devraient également bénéficier des résultats du projet proposé. En effet dès qu'il y a passage du texte à la parole ou de la parole au texte, les dictionnaires produits dans le cadre du projet seront immédiatement utilisables, d'autant que deux des partenaires du projet mènent des travaux en étroite liaison avec des équipes spécialisées en traitement de la parole.
Enfin, dans le chapitre III.3., les modules logiciels, les lexiques-grammaires et les résultats des travaux sur le compactage et l'organisation et l'accès à de grands volumes de données qui seront réalisés pendant l'exécution du projet proposé seront directement applicables. Ceci semble particulièrement important dans le cadre des sous-ensembles qui contiennent des travaux sur les interfaces homme/machine (III.3.2.1, III.3.2.2) ainsi que dans le sous-ensemble III.3.4.1. "système multisupport pour bases de données dans un environnement multilingue". Dans ce dernier sous-ensemble, les dictionnaires multilingues de mots composés, ainsi que les techniques de redressement morpho-syntaxique développées dans notre projet devraient fortement améliorer l'efficacité de la phase de transformation d'une phrase exprimées en langage naturel dans une requête à la base de données exprimée de façon indépendante de la langue initiale.
Dans les thèmes du type B du chapitre III.2.3. (Systèmes bureautiques), il en est un qui aurait pu être pris comme champ principal de ce projet tant est grande sa proximité. Il s'agit du thème "systèmes de soutien éditorial pour le traitement des langages sur la base des techniques IA et des normes ADB" Nous avons choisi de ne pas nous insérer dans ce champ de recherche car il nous a semblé qu'il serait plus intéressant de traiter le problème de la vérification et la correction morpho-syntaxique dans un cadre plus large que le cadre bureautique et en utilisant des techniques qui ne soient pas uniquement issues de l'IA. Ceci dit, il est bien clair que notre projet débouche sur des outils directement implémentables dans le cadre de projets bureautiques. Nous avions d'ailleurs envisagé, lors de la conception du projet, de prendre ce champ comme l'un des champs pour nos démonstrateurs.
Le projet que nous proposons est fortement demandeur d'échanges avec d'autres projets du programme de travail. Il en est ainsi, en particulier des projets qui entreront dans le sous-ensemble II.2.1 "système temps réel à base de connaissance" dans le chapitre "génie de la connaissance". Ce sous-ensemble est directement en amont du volet architecture matérielle et logicielle du présent projet. En effet, le présent projet dans son application industrielle de vérification et correction intégrée dans la chaîne de production éditoriale regroupe exactement les contraintes énoncées : fonctionnement en temps réel avec des contraintes dures en matière d'extraction de données, combinaison de traitements informatiques "classiques" et de traitements faisant appel aux techniques de l'intelligence artificielle, performances imposant des architectures parallèles. Le projet proposé est évidemment également très demandeur, pour les mêmes raisons, d'échanges avec les projets II.3.1 "calculateurs à architecture parallèle", et II.3.2. "architectures parallèles pour systèmes symboliques et déclaratifs".
Le projet proposé est également porteur d'échanges potentiellement fructueux avec le sous-ensemble II.2.2. "systèmes experts coopérants" dans le chapitre "génie de la connaissance". En effet les techniques mises en oeuvre en analyse morpho-syntaxique font qu'il est courant que, sur un même segment de texte, plusieurs systèmes experts travaillent (éventuellement en même temps) et fournissent des résultats (de recherche d'erreurs, de propositions de correction, de fragments d'analyse...) pour lesquels ils est nécessaire d'assurer coordination et arbitrage.
Pour ces sous-ensembles II.2.1., II.2.2., II.3.1 et II.3.2., il pourrait être envisagé que les modules logiciels et les lexiques-grammaires issus du présent projet fournissent une base pour des démonstrations d'implémentations.
On remarquera, dans les trois modules ci-dessus l'extrême contextualisation des textes. Dans le premier et le second module, le but est de montrer que les objectifs du programme proposé convergent étroitement avec ceux de la CCE (d'où l'emploi de termes comme "versatilité", "adaptabilité", "saut technologique qualitatif et quantitatif", "standardisation et normalisation"), cependant qu'il reste réaliste, c'est à dire capable de fournir des résultats exhibables dans le délai imparti de réalisation.
Le troisième module cherche simultanément, à fournir l'apparence de l'exhaustivité dans la description de l'état de l'art (afin de ne pas risquer une attaque pour méconnaissance du domaine), et de l'objectivité (afin de ne pas amener l'expert qui le lira à engager des recherches en vue de le valider). Parallèlement, ce module insiste sur les défaillances des systèmes existants qui, justement, correspondent aux objectifs du programme proposé. Enfin, le module pose des questions qui peuvent venir à l'esprit de l'expert en cours de lecture et y répond immédiatement. Il fait référence à des études que l'expert devrait avoir lues et, enfin, il positionne le projet dans la nomenclature du programme de l'appel d'offre, tout en s'efforçant de montrer que le porgramme proposé va bien au delà de son strict positionnement dans cette nomenclature. Bien entendu, puisqu'il s'agit d'un état de l'art, ce module donne l'argumentaire nécessaire sur la compétence des équipes participantes qui, évidemment, sont toutes à la pointe de leurs domaines respectifs...
On en arrive maintenant à la description effective du programme de recherche et développement. Cette description doit paraître évidente à l'expert, au vu de l'argumentaire antérieurement développé. Le but de l'introduction est le suivant. Etant donné que ce projet de programme est susceptible, en cas d'acceptation, de se transformer en un document contractuel (le contrat de versement des financements communautaires), il est absolument indispensable de prendre quelques précautions quant à la limite des résultats qui seront obtenus. Le ton de l'introduction de ce module est donc très prudent, pragmatique et précautionneux. En effet, au cas où le programme ne donnerait pas tous les résultats escomptés, il faudra les expliquer et donc, il sera fait référence au document contractuel initial pour y chercher des avertissements prélables. La rédaction n'est cependant pas ouvertement pessimiste car cela pourrait nuire à la (bonne) opinion que l'expert lecteur est déjà supposé se faire du programme.
II.7.- Description of the project
(Description du projet)
On a vu, dans le paragraphe précédent, les raisons qui ont amené à cibler le projet sur ce qui était le noyau de l'activité d'édition de textes : quelle que soit la thématique des projets existants, en matière de traitement automatique de la langue naturelle écrite (et peut être même parlée), ils se heurtent souvent au problème de la description morpho-syntaxique des langues. La vérification et la correction orthographiques semblent être l'une des thématiques les plus adéquates pour parvenir à des éléments de solution,
- parce qu'elle cerne de près le noyau du problème sans lui superposer de trop nombreux autres problèmes ;
- parce qu'elle s'ouvre vers une importante gamme de produits directement dérivés.
Issus de l'observation des travaux de recherche en cours ou des produits actuellement sur le marché, quelques autres considérations ont guidé la définition de ce projet :
- Peu de résultats industriellement exploitables peuvent être attendus à terme raisonnable en utilisant principalement des techniques basées sur la compréhension du sens des textes traités (à cause de leur caractère inéluctablement encyclopédique dans les applications envisagées), ce qui amène à choisir comme axe principal de développement l'analyse morpho-syntaxique des textes ;
- Il faut s'efforcer de mettre en oeuvre, dans le maximum de cas possibles, des descriptions exhaustives des phénomènes linguistiques qui peuvent être rencontrés, la finesse de ces descriptions étant le moteur principal des performances pour le système, mais la description exhaustive d'une langue naturelle n'est pas accessible en l'état actuel des connaissances ;
- L'utilisation de systèmes experts et des autres outils dérivés de l'intelligence artificielle (qui permettent une programmation déclarative et le traitement d'objets non totalement connus) est par conséquent impérative pour résoudre des problèmes locaux de linguistique à cause de l'insuffisance de connaissances ou de l'inachèvement des descriptions morpho-syntaxiques des langues considérées ;
- Les dimensions des dictionnaires et grammaires déjà disponibles chez les partenaires du projet et les dimensions des dictionnaires et grammaires qui sont visées dans le projet font que les temps de traitement sur les architectures matérielles actuellement commercialisées sont trop importants pour être acceptés par les usagers ;
- Les traitements linguistiques envisagés dans ce projet sont compatibles avec plusieurs possibilités d'organisations informatiques des matériels, des logiciels et des données ;
- Le système doit être conçu de façon à pouvoir être fortement modifié, tant au niveau des dictionnaires et grammaires qu'au niveau de son organisation logicielle, de façon à pouvoir s'adapter à la grande multiplicité des environnement d'utilisation. Dans la mesure du possible, le système doit s'auto-adapter, sans intervention de l'usager, à son environnement ;
- le système doit être conçu de façon à être réutilisable et former une base solide dans d'autres développements que la vérification ou la correction morpho-syntaxique ;
- C'est par le mariage entre une démarche essentiellement pragmatique dans l'implémentation et une grande solidité des bases scientifiques que le projet réussira. L'une des conditions de cette réussite est de disposer des bonnes informations : informations sur les textes que l'on corrige, informations sur les performances du système en cours d'élaboration.
La fabrication de deux appareillages de mesure est donc indispensable, dès les premières étapes du projet : une méthodologie de test et un outillage de mesure des performances du système de vérification-correction et un système de mesure qualitative et quantitative des erreurs générées par le couple (système de saisie/type de texte saisi).
- Dans ce projet où sont impliqués des partenaires fonctionnant dans des environnements réglés par des logiques différentes (par exemple, logique industrielle/logique universitaire, mais aussi logique industrielle française/logique industrielle italienne ou encore logique de PME/logique de filiale d'un grand groupe) la qualité et la rigueur de la gestion du projet sont un facteur essentiel de son succès.
II.7.1.- Main description (Description principale du projet)
Le projet se compose de sept sous-ensembles principaux et de deux modules de service.
II.7.1.1.- Architectures matérielles
Dans ce sous-ensemble, seront élaborées et testées différentes architectures matérielles destinées à accroître le parallélisme tout en prenant en compte les spécificités des traitements linguistiques.
Les problèmes de parallélisation des traitements se manifestent de plusieurs façons différentes et visent tous à accroitre fortement les performances des systèmes. En effet, l'augmentation de la taille des dictionnaires et la diversification des traitements provoque une explosion combinatoire qui se traduit par de très nombreux accès aux lexiques grammaires ou par des calculs. Deux exemples permettent de concrétiser cette explosion :
1.- Un module de détection des omissions de caractères (fréquentes dans une saisie manuelle) va, pour chaque forme graphique rencontrée, générer toutes les insertions possibles d'une lettre en intercalage entre chacune des lettres de la forme graphique. Un accès au dictionnaire sera fait pour chaque forme générée. Un calcul simple montre que, pour un mot de 7 lettres (longueur moyenne d'un mot en français) cet algorithme génére 27 fois 8 mots candidats, soit 216 mots.
2.- Un module de reconnaissance de mots composés de la forme N de N (par exemple, "étoile de mer" ou "tête de pont") avec une distance possible entre les éléments formant le mot composé (par exemple, un qualificatif avant le second N) va être activé pour toute occurrence du mot de.
Or ce mot est extrêmement courant en français où il est utilisé dans bien d'autres circonstances. Malgré la faible rentabilité de ce module (qui ne ramènera un mot composé que dans un appel sur 10 ou 20), il est cependant indispensable de le mettre en oeuvre car les règles d'accord et autres flexions de mots composés en N de N sont, en français, particulières et peu susceptibles d'algorithmisation.
On dispose actuellement de très peu de données sur le fonctionnement d'un ensemble important de modules de recherche d'erreurs et surtout de modules de génération de propositions de corrections, d'autant qu'il est très probable que dans des applications différentes, il y a une forte variation des traitements mis en oeuvre, ce qui amènera à envisager des solutions assez diversifiées.
Seront, en particulier examinées les architectures permettant de réaliser :
- des traitement identiques sur des segments de données différents, l'idée étant de segmenter les textes pour les amener à des sous-ensembles d'une dimension élémentaire sur lesquels un processus complet de vérification est mis en oeuvre. Cette possibilité se heurte à la difficulté de la segmentation : Des erreurs, telles que l'insertion d'espaces à l'intérieur de mots ou l'omission du point en fin de phrase provoqueront des disfonctionnements du système de segmentation. Par ailleurs, une segmentation trop fine (par mots) en même temps qu'elle facilite certains traitements (phonétisation, par exemples) en interdit d'autres (reconnaissance des mots composés ou désambiguïsation syntaxique). Mais une segmentation trop large (par phrase) présente d'autres inconvénients qui ne sont pas moindres, de telle sorte que seules des expérimentations systématiques permettront de faire les choix définitifs ;
- des traitements différents sur des segments de données identiques. Dans ce mode de parallélisation, trois problèmes principaux se posent : l'équilibrage de la puissance demandée par chacun des traitements mis en oeuvre de façon à gérer efficacement le défilement des segments examinés, la hiérachisation des traitements et la gestion des importants flux d'échanges entre les différents processeurs ;
- des accès à des mémoires identiques par des traitements identiques ou différents. On ne peut que difficilement envisager, actuellement du moins, une duplication complète des dictionnaires. Une parallélisation des accès à la mémoire est cependant l'un des facteurs principaux de performance d'un système de traitement automatique de la langue naturelle. Le problème est qu'un même traitement générera des quantités de requêtes extrêmement variables suivant les données sur lesquelles il est appliqué (on a vu plus haut, par exemple, qu'un module de recherche d'omission génère un nombre de requêtes qui est de 27 fois le nombre de lettres dans le mot examiné plus une). Il faut donc probablement envisager une séparation complète entre les traitements et les accès aux dictionnaires, considérant que des traitements différents peuvent demander des accès aux mêmes dictionnaires et que le volume des requêtes pour un même traitement est fortement variable.
II.7.1.2.- Architectures logicielles
Outre la mise au point des architectures logicielles qui correspondent aux architectures matérielles élaborées dans le sous-ensemble 1, on traitera dans ce sous-ensemble le problème de l'arbitrage entre des systèmes experts et des logiciels "classiques" de traitement linguistique. Il y aura, en effet, deux grandes classes de traitements simultanéments actifs :
- des traitements qui correspondent à des problèmes entièrement résolus du point de vue linguistique, que ce soit par énonciation ou par algorithme (ainsi en est-il, par exemple, des occurences de la lettre ù en français) ;
- des traitements qui correspondent à des problèmes non encore entièrement résolus et pour lesquels les techniques issues de l'IA permettent cependant des résolutions partielles (par exemple, la reconnaissance de mots issus de transformations telles que la superlativisation : belle se transforme en bellissime mais petit ne se transforme que difficilement en petitissime. Les règles de ce mécanisme étant, par ailleurs différentes en français et en italien).
Le problème des arbitrages est proportionnel à la quantité de modules d'identification d'erreurs et de modules de proposition de correction. En effet, plus le nombre de modules est grand, plus l'analyse est fine et donc plus le nombre de propositions s'accroît. Mais ces propositions, sont, pour la plupart, des fausses détections d'erreurs et des propositions inadéquates de corrections. L'arbitrage entre les résultats des traitements se fait à un niveau logiciel supérieur faisant appel principalement à des modules de traitement syntaxique mais pouvant, en rétroaction, faire appel aux modules de base : la proposition d'un module est réinjectée dans un pseudo-texte et proposée en correction. Si une erreur est à nouveau détectée, la proposition est abandonnée. Très peu de travaux ont été, à ce jour, menés sur ce thème, aussi plusieurs techniques différentes d'arbitrage devront être élaborées et testées.
Par ailleurs, une architecture permettant au système de se reconfigurer dynamiquement en fonction des spécificités et évolutions des applications en cours sera mise au point. L'idée de base est la suivante :
En fonction de l'application en cours, le système doit être capable d'optimiser son propre fonctionnement. Un exemple simple de ce mécanisme est le suivant : Dans un quotidien de la presse sportive, il peut apparaître que le taux d'erreur sur les noms propres des sportifs est important par rapport aux autres erreurs. Le système va donc reconfigurer ses modules de traitement et ses dictionnaires de façon à privilégier le traitement des noms propres. Bien entendu, cette variabilité est récursive et liée au couple (système de saisie-genre de textes traités), ce qui fait que le système est quasiment en reconfiguration permanente, un simple changement de claviste ou même la fatigue provoquant des erreurs très différentes sur un même texte. La notion de "genre de texte" n'est ici introduite que pour l'exposé, car il n'est pas question de faire une segmentation à priori des genres de textes. Le système fera sa propre segmentation sans intervention humaine.
Enfin, de nouveaux modules de détection et de correction d'erreurs morpho-syntaxiques seront développés. Un travail de recherche sur les ergonomies des applications et sur les fonctionalités des mécanismes de mise à jour des dictionnaires et grammaires sera fait en vue de faciliter la réalisation, à partir des outils disponibles, de configurations adaptées à des classes d'applications différentes.
II.7.1.3.- Architectures de dictionnaires
Les dictionnaires existants seront considérablement augmentés, afin d'améliorer la couverture linguistique des langues choisies (français, espagnol, italien). De nouvelles techniques de compactages formel et linguistiques des dictionnaires seront élaborées et testées, ainsi que des méthodes d'accroissement automatique contrôlé.
Pour ce qui est de techniques de compactage formels, on sait que l'analyse en temps réel d'une chaîne de phonèmes perçus pour transcrire le discours parlé nécessite l'emploi de méthodes probabilistes portant sur les fréquences de multigrammes et, plus généralement, sur tous les accidents de la phrase qui permettent de procéder à cette restitution. Les méthodes probabilistes employées dans ce cas relèvent de la théorie des processus et, en particulier, de sa version plus simple, celle des processus de Markov.
Le compactage des textes et dictionnaires suppose également une analyse statistique que l'on aimerait pouvoir effectuer en temps réel, ce qui nécessite des méthodes nouvelles. De la même façon, l'étude des fréquences, non plus de multigrammes mais de structures syntaxiques, qui conduirait à probabiliser les grammaires, ouvre un vaste champ de recherche. C'est dans ce champ, par exemple, que se situe le problème très anciennement posé mais non encore résolu, des grammaires "tolérantes aux fautes" (quelques fautes d'orthographe ne modifiant pas la structure syntaxique que l'on est amené à donner à la phrase).
Pour ce qui est des compactages linguistiques, un simple exemple montre la différence entre la structure de dictionnaires existants (développés pour l'usage par des humains) et la structure des dictionnaires qui seront utilisés dans le projet :
Le verbe "manger", qui fait l'objet d'une entrée unique dans le dictionnaire d'usage, apparaît comme "éclaté" en plus de 90 entrées correspondant chacune à un verbe considéré comme distinct des autres dans la mesure où ils possèdent des propriétés sémantiques et syntaxiques spécifiques.
Les exemples qui suivent sont des phrases déclaratives simples qui comportent chacune le verbe "manger". Les codes alphanumériques qui précèdent chaque phrase sont les noms des clases syntaxiques auxquelles appartiennent ces verbes considérés comme distincts :
38LO Max mange sa soupe dans un bol
35R Max mange au restaurant
32C La rouille mange le fer
36DT Ce travail mange du temps à Max
32R2 La barbe de Max lui mange le visage
32L Cet arbre mange notre vue sur la mer
32R3 Max mange son crayon
32R3 Max a mangé son héritage
32R3 Cette compagnie mange de l'argent
32R3 Ma voiture mange beaucoup d'essence
32H Max n'a jamais mangé personne
Outre ces 10 entrées, on relève 80 formes figées (verbes et adverbes complexes), dont :
C1 Max a mangé du lion
C1 Max a mangé le morceau
PV Max est bête à manger du foin
Chaque classe syntaxique correspond à une structure syntaxique particulière. Tous les sens et nuances de sens de tous les mots doivent être systématiquement répertoriés et formalisés.
A titre de comparaison, on trouvera dans le tableau de la page suivante
des données linguistiques telles qu'elles sont structurées
dans une base de données "mère" à usage dictionnairique
général (destinées à un usage par des humains).
![]()
fig. 3 L'articulation des dimensions lexicographiques ; exemple sur un extrait de l'article "coudre" du Dictionnaire général Hachette.
On voit que l'on est encore loin des descriptions directement utilisables dans un système de vérification orthographique mais que, cependant, commencent à apparaître des informations qui peuvent être réexploitées, le problème cependant est que la plupart des dictionnaires (pour l'usage par des humains) existants ne sont pas issus de bases de données "mère", ce qui signifie qu'il faut reconstruire, quand cela est possible, les informations nécessaires à partir des structures typographiques des documents. Des essais seront tentés pour mesurer la validité de ces procédures d'extraction et la rentabilité de telles procédures.
En terme de compactage linguistique, la base de travail sera la réalisation de dictionnaires de préfixes, de racines et de suffixes dont seront dérivés les algorithmes et tables de manipulation. Des techniques particulières seront développées pour les dictionnaires de noms propres et les dictionnaires de sigles et abréviations.
Des structures, principalement non-alphabétiques, de dictionnaires seront systématiquement testées pour les architectures logicielles et matérielles développées dans les sous-ensembles 1 et 2, afin d'augmenter les performances des accès, principalement en génération de propositions de corrections. Un exemple typique de telles structures spécialisées de dictionnaires est celle d'un dictionnaire qui peut être utilisé dans un module de détection d'inversions de lettres (spychologie au lieu de psychologie). Une structure efficace et qui permet d'éviter la génération de toutes les inversions possibles dans le mot est la suivante : les lettres qui forment chaque mot du dictionnaire sont ordonnées par ordre alphabétique (psychologie devient ceghiloopsy). Un traitement identique est appliqué au mot en cours de contrôle et une simple comparaison ramène la graphie correcte. Aucune étude systématique de telles structures n'a été menée à ce jour. Elle sera réalisée pour chacun des modules de traitement développés dans le sous-ensemble 2.
II.7.1.4.- Traitements des mots composés
Aucun travail de recherche de grande ampleur n'a été réalisé à ce jour sur le traitement des mots composés alors même qu'apparaît l'importance croissante de cette classe d'objets dans le traitement automatique du langage naturel. On trouvera en annexe 1 des exemples de listes de telles formes dont le dénombrement approximatif fait apparaître que leur fréquence est très importante. La résolution, même partielle du problème de la reconnaissance des principaux types de mots composés permet, en effet de considérablement simplifier l'analyse syntaxique des textes, de même d'ailleurs que leur traduction dans d'autres langues.
L'accent sera mis sur les techniques d'élaboration de grands dictionnaires de mots composés, en particulier dans les vocabulaires scientifiques et industriels. Des algorithmes de recherche et d'identification de candidats mots-composés dans des textes seront élaborés. Des méthodes de génération automatique et de normalisation des flexions et des graphies seront mises au point et testées. Différentes architectures de grands dictionnaires seront envisagées afin d'optimiser les accès et les mises à jour. Les liaisons entre dictionnaires de mots composés et dictionnaires de mots simples, d'une part, et entre dictionnaires de mots composés dans des langues différentes, d'autre part, seront examinées et feront l'objet de propositions de mise en oeuvre.
II.7.1.5.- Intégration
Dans ce sous-ensemble, deux démonstrateurs d'intégration des outils développés dans les sous-ensembles précédents seront développés.
Le premier consistera en une implémentation dans une chaîne de production éditoriale multiusages de grande taille. Cette chaîne, qui est actuellement en fonctionnement chez l'un des partenaires du projet, comprend un réseau local sur lequel sont connectés des ensembles fonctionnels de saisie humaine et automatique, corrections et transformations typographiques, fabrication de schémas, plans, croquis et dessins, numérisation de documents, mise en page automatique ou semi- automatique, photocomposition. Elle est utilisée pour des productions extrêmement variées, allant de manuels scolaires à des documentations techniques en passant par des dictionnaires et des bases de données bibliographiques. Avant la réalisation du démonstrateur, des tests de validation permettront de définir les points d'insertion du système dans la chaîne. L'un des problèmes principaux sera de ne pas troubler la circulation des flux de données entre les différents ensembles fonctionnels. Un autre problème sera de maintenir la productivité des intervenants humains. En particulier, l'implémentation devra tenir compte de la nécessité de ne pas casser la productivité des clavistes et des correcteurs (humains), en particulier par un accroissement des fausses alertes. Enfin, l'implémentation devra intégrer les nécessités de l'interfaçage avec des systèmes hétérogènes (allant jusqu'à des codages différents des caractères dans les sous-ensembles fonctionnels) et maintenir l'intégralité des informations typographiques sur les textes entrés.
Le second démonstrateur consistera une implémentation en sortie d'un système professionnel de lecture optique de caractères. Il devra alors, autant que possible, prendre la forme d'une "boîte noire" minimisant les interactions avec l'opérateur humain du lecteur optique. Cette implémentation pourra, au choix être appliquée seulement en cas de non-reconnaissance par le lecteur (avec pour objectif de minimiser le nombre des interventions de l'opérateur humain) ou bien sur l'ensemble du texte (ce qui vérifiera également les fautes de frappe dans l'original qui ont été correctement lues par le lecteur optique).
Pour ces deux démonstrateurs, les critères de performances principaux seront :
- pour la partie vérification, le rapport erreurs détectées/erreurs réelles parmi l'ensemble des erreurs détectées ;
- pour la partie correction, le pourcentage moyen de pertinence de la première correction proposée.
Dans le cas de la correction appliquée seulement sur les défaillances du lecteur optique, le critère sera le pourcentage d'interventions humaines évitées sans introduction d'erreur supplémentaire.
II.7.1.6.- Métrologie et validation
Une méthodologie générale de mesure des performances et de tests de systèmes de vérification ou de correction morpho-syntaxique de textes sera mise au point. Une liste des indicateurs de performances sera établie avec, pour chacun des indicateurs, la méthode permettant de procéder au test. Pour les tests qui le nécessiteront, un double corpus de référence sera fabriqué : corpus avec fautes quantitativement et qualitativement représentatives et corpus corrigé à 100%. Les logiciels correspondants seront développés de façon à être applicables au plus grand nombre possible de systèmes. La méthode de test sera élaborée de telle sorte que chacun des modules d'un système puisse, lorsqu'il le permettra, faire l'objet d'une analyse séparée. Les corpus de référence seront construits pour les trois langues choisies dans le projet. Une méthodologie de développement de corpus semblables sera proposée pour l'ensemble des langues à alphabet latin.
II.7.1.7.- Analyse des erreurs
Une méthodologie d'analyse et de typologie qualitative et quantitative des erreurs commises dans un couple (système de saisie-domaine d'application) sera développée en prenant en compte la possibilité de systèmes de saisie non-humains. Les logiciels correspondant seront développés avec possibilité d'intégration dans des systèmes d'auto-configuration dynamique d'automates vérificateurs et correcteurs. Cette méthodologie fera l'objet de deux démonstrateurs choisis dans les mêmes champs que les démonstrateurs du sous-ensemble 5.
II.7.1.8- Module de service "Documentation et communication"
Ce module est un service commun à toutes les équipes qui sont partenaires du projet. Il est destiné à alimenter les équipes en informations sur les différents aspects des recherches en cours. Il sera mis en place dès le début du projet et se poursuivra pendant toute sa durée. Il fournira plusieurs services différents :
- Une bibliographie de départ sera élaborée, qui réunira le maximum de données disponibles par interrogations systématiques des grandes bases de données bibliographiques mondiales, et par collecte des études techniques et commerciales réalisées ces dix dernières années dans le domaine ainsi que par recherche systématique de la littérature grise accessible. La structure de cette bibliographie correspondra aux différents sous-ensembles du projet. Le module fournira, sur demande (transmises via la messagerie électronique), les documents primaires aux partenaires du projet.
- Un fichier mondial des experts susceptibles d'être interrogés sur les différents problèmes qui sont rencontrés par les équipes en cours de travail.
- Un fichier mondial des entreprises et des produits liées par l'amont ou par l'aval au projet en cours.
- Une veille technologique sur les produits de vérification ou de correction orthographique commercialisés ou en cours de développement ainsi que sur les colloques, congrès et salons susceptibles d'apporter des informations aux partenaires.
- Une diffusion sélective et personnalisée de l'information pour chacune des personnes venant participer au projet.
- Un suivi des autres projets ESPRIT qui sont liés, en amont ou en aval, au projet en cours, avec l'organisation de rencontres entre les différents projets.
- La gestion du système de messagerie électronique entre les participants avec édition des principaux débats techniques pour diffusion interne et externe.
- L'organisation des rencontres régulières entre les participants pendant toute la durée du projet.
- L'organisation des rencontres avec les experts désignés par la Commission pour suivre le développement du projet.
- La mise en forme, l'édition et la publication des rapports des participants au projet.
II.7.2.- Le plan de travail et le PERT du projet
Ce plan de travail est composé des éléments suivants :
- Un schéma des relations entre les différents modules du projet
- Un schéma PERT général des principales tâches qui seront réalisées.
La présence de ces deux éléments est quasiment formelle car elle n'apporte rien au descriptif du projet. Il est cependant indispensable de montrer à l'expert la capacité des équipes à s'organiser, même si, dans la pratique, le Pert ne sera pas (ou peu) utilisé. La figure 4 ci-dessous présente un autre intérêt, c'est celui de pouvoir être utilisée comme transparent rétroprojecté au cas où il sera demandé aux partenaires du projet de faire un exposé de présentation dans le cadre de demandes d'informations complémentaires.
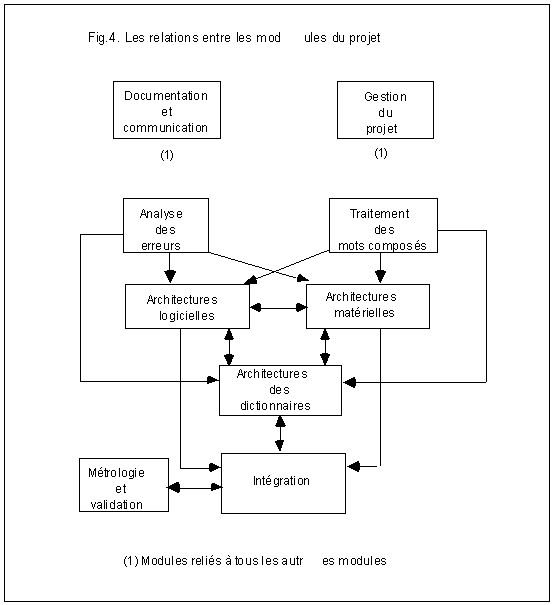
Après avoir décrit le programme, il faut valoriser la demande financière. Pour des raisons évidentes, cette partie est présentée de façon courte et neutre dans sa partie textuelle, les chiffres étant donnés par ailleurs, dans des tableaux financiers. Ce qu'il faut savoir, c'est que, le détail des aspects financiers n'est pas considéré comme important, aussi bien par les décideurs que, à un moindre niveau, par l'expert. Ce qui compte dans le processus de décision, c'est le montant total engagé dans l'opération et la répartition entre les investissements matériels et les autres dépenses.
Examinons, pour commencer, les conditions que doit respecter le montant total engagé pour que le projet ait des chances d'être accepté. Ce montant peut être :
- du même ordre que le plus haut montant de dépenses des autres projets présenté. Il faut alors que le dossier soit d'un niveau qui le place au dessus du niveau général des projets présentés. Cette carte peut être jouée, mais elle implique que les partenaires soient, de façon incontestable, les leaders européens du domaine. On ne prête qu'aux riches...
- dans la moyenne des montants des autres dossiers présentés. C'est le cas favorable où le projet est "noyé dans la masse" et donc n'attirera pas l'attention dans les négociations de décision. Le montant de cette valeur moyenne peut être généralement obtenu par un bref entretien avec l'un des fonctionnaires chargés de la gestion des appels d'offre. On peut également le calculer simplement en divisant le montant total des fonds disponibles par le nombre estimé de projets qui seront présentés. Cette estimation du nombre de dossiers présentés est plus facile encore à obtenir que la précédente auprès des fonctionnaires européens, car c'est une information publique.
- du même ordre de grandeur que le plus faible montant des dépenses dans les autres projets. Cette stratégie de tout ou rien repose sur l'argumentaire simple qui veut que soit le dossier sera accepté pratiquement sans évaluation "parce qu'il ne coûte pas cher", soit le dossier sera éliminé parce que jugé inopportun et non cohérent par rapport aux autres. Une bonne façon de provoquer la concrétisation de la première possibilité est de mettre comme partenaire du projet un partenaire d'Etat très en retard technologiquement. Cela permet de faire intervenir un argumentaire du type "cela ne coûte pas cher et, en plus, cela permet de dire que l'Etat X présente un projet qui a été accepté". En effet l'un des indicateurs de l'égalitarisme obligatoire que maintient la CCE entre les Etats membres est le nombre de projets acceptés dans chaque Etat (même si, en valeur, certains de ces projets sont négligeables). Cette stratégie misérabiliste n'a évidemment de chances de fonctionner que si elle est pratiquée par un nombre restreint de proposants.
Pour ce qui est de la répartition des dépenses entre les investissements matériels et les autres dépenses (composées le plus souvent principalement des salaires), la logique de raisonnement est qu'il ne faut pas que le financement accordé puisse être soupçonné d'être une aide qui soulagerait le bénéficiaire de dépenses qu'il aurait dû nécessairement engager même si le projet proposé n'était pas accepté. Ce soupçon pèse potentiellement sur tout investissement en équipement, surtout pour les partenaires issus des milieux de la recherche publique. On a donc intérêt à minorer ces dépenses.
Voici, en conséquence, le module de texte qui traite de ces deux aspects :
II.7.3.- Equipements principaux et moyens nécessaires
Le projet ne nécessite pas d'investissements de grande ampleur, l'essentiel des coûts résultant de travail humain. Les investissements en équipement prévus dans le cadre de ce projet ne concernent donc que des équipements légers qui sont principalement destinés à deux objectifs :
- l'homogénéisation des équipements des partenaires qui développent les dictionnaires et la partie logiciels linguistiques, de façon à simplifier les échanges de données et de programmes.
- L'acquisition de modules électroniques, lorsqu'ils sont déjà commercialisés, (par exemple, des transputers ou des cartes parallèles NCR) qui permettent de développer des architectures parallèles sans avoir, à chaque fois, à totalement construire les éléments des prototypes.
On aborde maintenant une partie du dossier qui demande de la part du rédacteur une certaine attention. En effet, ce module sera intégré entièrement dans les documents contractuels rédigés en cas d'accceptation du projet. Les preuves matérielles de la bonne exécution du programme de recherche et développement doivent évidemment présenter toutes les apparences de la validité juridique. Elles doivent également démontrer que les partenaires acceptent un contrôle effectif des fonctionnaires de la CCE sur le déroulement du travail. Mais, en même temps, elles ne doivent pas constituer pour les partenaires une activité bureaucratique lourde et prenante, non plus qu'un frein si des orientations nouvelles venaient à apparaître en cours de programme. Enfin, il convient de ne pas inclure, dans les obligations contractuelles, l'obligation de fournir les produits eux-mêmes afin, d'une part, d'éviter des fuites dans le dispositif de secret industriel qui accompagne nécessairement la réalisation de programmes de dévelopement technologique et, d'autre part, de s'engager à fournir des produits qui, peut-être, ne seront pas réalisés, quelles qu'en soient les raisons. Ceci explique les termes de "présentation" et de "justificatif" qui sont utilisés à chaque fois que la réalisation d'un produit doit être prouvée aux fonctionnaires européens chargés du suivi du programme.
Voici la liste des engagements pris dans le cadre de ce projet :
II.7.4.- Liste des objets contractuels résultants des travaux
Dans ce qui suit, il est supposé que les contrats sont signés en juin 1988. Un retard à ce niveau provoquera un décalage correspondant des échéances. Dans le PERT qui a été présenté précédemment, cette même date de signature a été prise comme point de départ, la durée prévue de chaque tâche étant affichée (en mois) dans le coin supérieur droit et la date prévue de début dans le coin supérieur gauche du cadre qui entoure le nom de chaque tâche. Dans ce PERT n'ont été présentés, pour ne pas alourdir le schéma, que les rapports d'étapes, qui sont au nombre de deux et qui correspondent à l'achèvement de phases importantes du projet. Cependant d'autres documents et produits intermédiaires seront fournis tout au long du projet :
En décembre 1988, le responsable technique général et le responsable financier général fourniront un rapport de mise en place du projet qui décrira l'ensemble du dispositif et les éventuelles évolutions par rapport aux prévisions initiales. Il est proposé que les représentants de la CCE, s'ils le souhaitent puissent alors rencontrer chacune des équipes au cours d'un bref voyage de cinq jours.
En juin 1989, chacun des partenaires fournira un rapport d'avancement technique et financier des travaux préparatoires et des premières expérimentations. Le tableau d'affectation des équipes aux différentes tâches donne le contenu de chacun des rapports.
En décembre 1989, le responsable technique général décrira les résultats des expérimentations préparatoires et explicitera les choix techniques faits en vue de la première intégration (prototype E1) dans un rapport des choix techniques.
En juin 1990, chacun des partenaires fournira un rapport d'étape technique et financier qui contiendra :
- Les résultats de l'analyse des performances du prototype E1;
- Une première version de la méthodologie générale de mesure des performances et de validation ;
- Une première version de la méthodologie d'analyse des erreurs ;
- Une liste des propositions d'amélioration ou de modification des choix techniques initiaux ;
- Un état d'avancement de l'accroissement des dictionnaires de mots simples ;
- Une situation financière du projet.
Ce rapport sera accompagné d'une présentation du prototype E1, destinée aux représentants désignés par la CCE, et de la fourniture d'un justificatif des dictionnaires de mots simples réalisés.
En juin 1991, chacun des partenaires fournira un second rapport d'étape technique et financier qui contiendra :
- Les résultats de l'analyse des performances des prototypes E2 et L1;
- Une version définitive de la méthodologie générale de mesure des performances et de validation ;
- Une version définitive de la méthodologie d'analyse des erreurs ;
- Une liste des propositions d'amélioration ou de modification des choix techniques ;
- Un état d'avancement de l'accroissement des dictionnaires de mots simples ;
- Un état d'avancement des recherches sur le traitement des mots composés ;
- Une situation financière du projet.
Ce rapport sera accompagné d'une présentation des prototypes E2 et L1, destinée aux représentants de la CCE, d'une copie des documents et des logiciels de méthodologie de mesure de performances et d'analyse des erreurs, d'un justificatif des dictionnaires de mots simples réalisés.
En juin 1992, chacun des partenaires fournira un rapport final, technique et financier, du projet. Ce rapport sera accompagné d'une présentation des deux démonstrateurs, d'un justificatif des dictionnaires de mots simples et de mots composés réalisés.
Il est nécessaire de fournir également des élements d'information sur la façon pratique dont sera organisée la coopération et la communication entre les partenaires du programme de recherche et développement. Le but de ce module de texte est de rassurer le lecteur quant à la capacité d'organisation des demandeurs. Une bonne façon de parvenir à ce but est de proposer une organisation de la gestion du projet qui soit calquée sur les organisations mises en place pour gérer des projets dans les administrations européennes.
Deux éléments clé sont présents dans ces organisations :
- une autorité "morale" et "technique" supérieure qui gère le projet par voie de consensus en assurant un suivi permanent de l'évolution de la situation.
- un contrôle financier chargé de garantir le respect des règles comptables imposées par la CCE.
A l'évidence, ces deux éléments clé sont présents, en plus de leur rôle structurel, pour dialoguer avec les fonctionnaires de la CCE qui suivront le programme et leur fournir, sous la forme appropriée, les documents qui permettront à ces mêmes fonctionnaires de développer à leur tour une argumentation au sujet du bon fonctionnement du programme. En effet, si le programme venait à mal se dérouler, les fonctionnaires chargés de son suivi devraient en expliquer les raisons. Ils risqueraient d'être soupçonnés de ne pas avoir fait correctement leur travail d'évaluation initiale puis leur travail de suivi de programme ou de réorientation en cas de problème inattendu. Et donc, quel que soit le résultat effectif du programme, les fonctionnaires européens, tout comme les partenaires ont intérêt à donner à l'ensemble des documents probatoires l'apparence d'un bon fonctionnement.
Il faut préciser ici que, du point de vue de la rationalité d'un fonctionnaire de la CCE, un programme se déroule mal s'il est arrêté en cours de route, même si les raisons de l'arrêt sont d'ordre scientifique? S'il est normal, dans la rationalité scientifique d'explorer des branches mortes et donc d'interrompre parfois des activités de recherche et développement, par contre, dans la rationalité "européenne" un arrêt est assimilé à une mauvaise évaluation initiale et donc à une erreur des fonctionnaires de la CCE.
Voici donc le module qui décrit l'organisation de la gestion du programme :
II.7.5.- Description de la gestion du projet
1.- Gestion technique du projet
Dans les deux mois qui suivront la signature des contrats, un Comité de gestion technique du projet sera mis en place. Ce Comité sera dirigé par un responsable technique général désigné par le chef de file des contractants.
Il sera composé :
- des responsables techniques désignés par chacun des partenaires impliqués dans le projet ;
- du responsable de la gestion financière du projet, à titre d'observateur ;
- des représentants désignés par la CCE pour suivre le projet ;
- du responsable de la cellule documentation et communication.
Ce Comité technique se réunira au moins une fois par trimestre dans son ensemble.
Ce Comité Technique aura la charge :
- de définir précisément la répartition des tâches et des responsabilités techniques entre les partenaires ;
- de superviser l'engagement des personnels nécessaires au projet ;
- de surveiller le respect des temps alloués à chaque tâche ;
- de décider des mesures nécessaires à la coordination technique entre les tâches ;
- de faire les choix techniques à la fin de chaque phase d'expérimentation ;
- de vérifier la bonne fin d'exécution des différentes tâches ;
- de superviser la fourniture à la CCE des rapports techniques d'étape et des produits intermédiaires prévus;
2.- Gestion financière du projet
La gestion financière du projet sera assurée par chacun des partenaires pour la partie qui le concerne. Cependant, un responsable financier général sera désigné par le chef de file des partenaires. Il aura pour tâche de s'assurer de l'adéquation entre les dépenses et les travaux exécutés ainsi que de regrouper les informations provenant des différents partenaires afin de les transmettre à la CCE dans les rapports financiers intermédiaires. Au moins une fois tous les semestres, les responsables financiers du projet se réuniront, en phase avec les réunions des responsables techniques afin de faire un point de la situation financière du projet en présence des représentants de la CCE.
On arrive maintenant à la partie finale de la description de ce programme de recherche et développement. Cette partie n'apporte rien de nouveau quant au contenu technique proprement dit mais insiste sur les relations avec les autres programmes soutenus par la CCE. Elle se termine sur l'habituelle phrase emphatique dont le thème pourrait être résumé par "la CCE se doit d'être à l'avant garde de la technologie", et en sous entendant qu'elle ne manquera pas de prouver par l'intermédiaire de l'expert qui acceptera le projet présenté !! Cet argument a plus de poids qu'il n'apparaît au premier abord car il touche directement à un point de la rationalité affichée du fonctionnaire européen. En effet, quelle que puisse être l'opinion personnelle de l'expert, quand il a choisi de travailler pour la CCE, il a, simultanément, pris l'obligation de tenir, par rapport à l'extérieur en tout cas, un discours européen dans lequel les institutions communautaires sont destinées à se substituer progressivement aux institutions nationales et doivent donc, de ce fait, se positionner dans tous leurs domaines d'intervention, au niveau le plus élevé.
Voici donc ce dernier paragraphe du texte de défintion du programme de recherche et développement d'un vérificateur orthographique professionnel multilingue.
II.7.6.- Relationships with other programmes
Les relations souhaitées avec les autres programmes ESPRIT ont été décrites dans le paragraphe II.6. du présent projet. Le PERT du projet montre clairement qu'il serait souhaitable de disposer, dès le mois de mai 1989, des premiers résultats des autres projets ESPRIT qui portent sur les architectures parallèles et sur les techniques d'arbitrage entre systèmes experts et systèmes classiques. Ces deux problèmes sont en effet sur le chemin critique du PERT. Le projet sera en mesure de fournir des résultats à d'autres projets ESPRIT dès le mois de juin 1990. A cette date, en effet, les dictionnaires de mots simples et les algorithmes de vérification auront très probablement atteint des niveaux suffisants pour pouvoir être intégrés dans de multiples applications qui ne demandent pas une aussi grande précision que la vérification et la correction généralisée. En particulier ces données et logiciels devraient fortement intéresser les projets en bureautique et les projets qui contiennent des développements d'interfaces homme-machine en interrogation de bases de données ou en systèmes experts. Dans ses étapes finales, le projet pourra fournir des outils permettant de considérablement améliorer le fonctionnement de produits développés dans le cadre d'autres projets qu'ESPRIT. En particulier, il peut être prévu une interface avec le projet EUROTRA ou avec les développements d'autres système d'aide à la traduction menés à l'intérieur de la CCE. Le projet sera, par ailleurs coordonné avec les projets nationaux (en Espagne, Italie et France) menés en matière d'industries de la langue, lorsqu'ils verront le jour, car plusieurs des partenaires du projet joueront très certainement dans ces actions des rôles de premier plan.
Il est d'ailleurs probable que l'initiative que prendrait la CCE en participant au financement du présent projet, sera un facteur décisif dans la concrétisation des multiples programmes dans le domaine qui sont, à ce jour du moins, pratiquement restés lettre morte.